轻舟源规则介绍
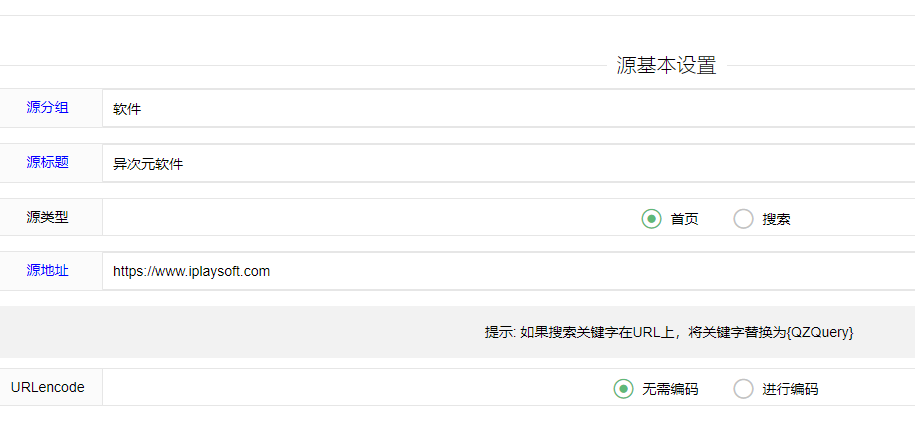
1. 源类型 :
选择首页或搜索.
2. URLencode :
如果需要urlencode勾选“进行编码”即可,少部分网站需要编码。
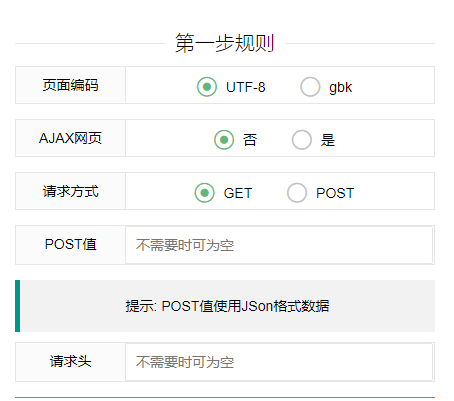
1.页面编码 :
一般为utf-8,如果获取的数据乱码切换为gbk。
2.AJAX网页 :
部分网页查看源代码没有所需要的数据,一般是网站使用js加载数据,勾选“是”后会模拟浏览器等待网页执行完js,因此耗时比较长。
3.请求方式 :
GET 和 POST。
4.POST值 :
POST时输入post的数据,JSon格式,例如:
{"name":"a","age":"18"}
5.请求头 :
部分网站需要请求头才能有效获取数据,或者带cookie模拟登录,JSon格式,例如:
{"cookie":"xxxx","user-agent":"xxxx"}
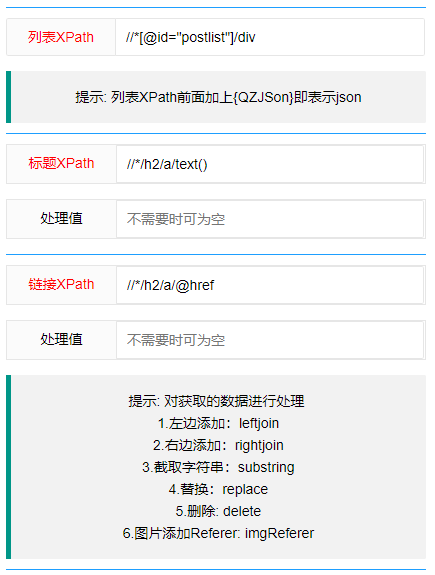
1.列表Xpath :
xpath选择器获取,表示多个数据
2.标题Xpath :
从列表Xpath获取的数据中循环获取标题
3.处理值 :
标题的处理
4.链接Xpath :
从列表Xpath获取的数据中循环获取链接
5.处理值 :
链接的处理
处理值
处理类型目前共有6个:
1.左边添加:leftjoin
2.右边添加:rightjoin
3.截取字符串:substring
4.替换:replace
5.删除: delete
6.图片添加Referer: imgReferer
左边添加例子:
1.获取的链接前面加上域名:{"type":"leftjoin","value":"http://www.xx.com"} 2.获取的链接前面为当前链接(特殊情况):{"type":"leftjoin","value":"{QZLink}"}
右边添加例子:
1.构造下一页:{"type":"rightjoin","value":"&page={QZPage}"}
截取字符串例子:
1.从style属性中获取图片地址{"type":"substring","value":"22,-1"}
替换例子:
1.普通替换:{"type":"replace","value":"要替换的字符串,新字符串"} 2.删除:{"type":"replace","value":"要删除的字符串"}
删除例子:
1.标题下处理表示不显示包含该字符串的标题:{"type":"delete","value":"首页"}
图片添加例子Referer:
仅图片使用,图片防盗链时添加Referer
1.{"type":"imgReferer","value":"http://www.xx.com"}
2.Referer为当前解析步骤的url时:{"type":"imgReferer","value":"{QZLink}"}
处理复杂情况时多个处理用大括号包裹:
[{"type":"leftjoin","value":"http://www.xx.com"} {"type":"replace","value":"xx,xxx"} ,{"type":"rightjoin","value":"&page={QZPage}"} ]
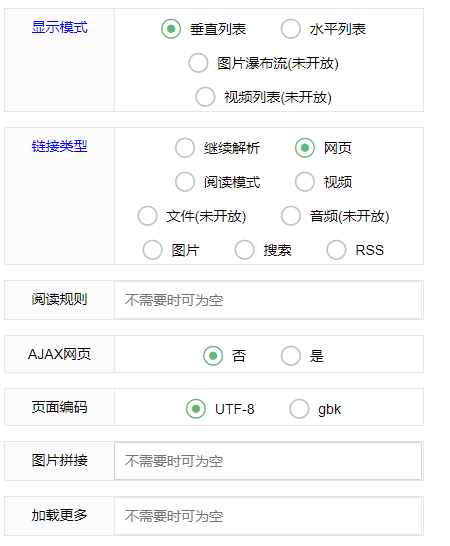
1.链接类型 :
1.继续解析 : 继续处理数据 进入下一步
2.网页 : 使用软件内自带浏览器打开链接
3.阅读模式 : 只显示文字 小说阅读
4.视频 : 使用视频播放器打开链接
5.图片 :显示图片列表
6.搜索 : 使用标题进行搜索
7.RSS : rss使用另外的rss源制作工具
2.阅读规则 :
小说:使用xpath或select规则 例如:div[id="content"] div[class="TXT"]
图片: 使用xpath或js 例如: //*[@class="xx"]/div/img/@src
3.图片拼接:
如果图片使用xpath获取的图片不完整,使用处理值的方式对图片进行处理:
{"type":"leftjoin","value":"http://www.xx.com"}
如果图片防盗链,使用:
{"type":"imgReferer","value":"http://www.xx.com"}
或者:
{"type":"imgReferer","value":"{QZLink}"}
也可以直接简写为:
{QZLink}
4.加载更多:
与加载下一页相同,使用处理值方式获取下一页url 例如:
{"type":"rightjoin","value":"{QZPage}.html"}
如果列表获取的顺序需要反转,在前面加上“反” 例如:
反{"type":"rightjoin","value":"{QZPage}.html"}